これはなに?
前回のブログに引き続いて、ポルカの歌詞分析やっていきます。
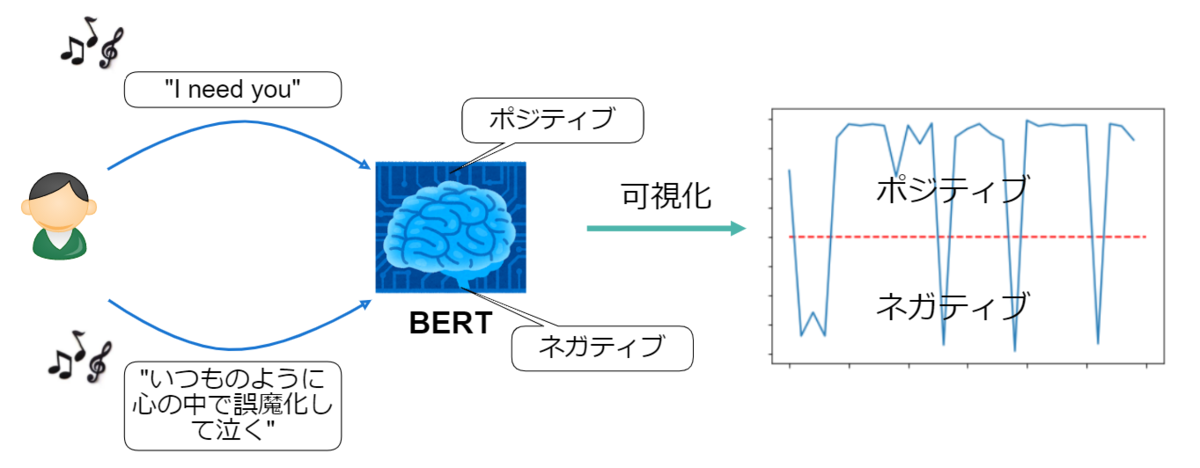
今回はBERTを使って歌詞の感情分析を実施し、曲中の感情の変化を可視化してみます。
www.cloudnotes.tech www.cloudnotes.tech
BERTとは
Googleが2018年に発表した言語モデルで、2019年からGoogleの検索エンジンにも、BERTの言語モデルが利用されています。
[1810.04805] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
ロジックとか難しいことは、参考記事を参照していただいて、BERTのユースケース以下です。
- 含意関係の分類
- 質問内容が同じであるかを分類
- 質問と文が与えられ文が質問の答えになるか当てる分類
- 映画のレビューに対する感情分析
- 文の文法性判断を行う分類
- 2文の類似度を5段階で評価する分類
- ニュースに含まれる2文の意味が等しいかを当てる分類
- 小規模な含意関係の分類
今回はユースケースの5番の感情分析をBERTを使って実施していきます。
■参考
BERTについて解説!日本語モデルを使って予測をしてみようー!|スタビジ
やること
ポルカのいくつかの歌詞をピックアップして、文章に分割します。
分割した文章をBERTモデルで感情分析し、分析結果を取得、可視化します。
■ イメージ図
環境
今回も以下の記事のDocker環境を利用します。
日本語BERTの動作確認

モデルに文章をインプットすると、アウトプットとして、ポジネガの判定結果と度合いが返ってきます。
■ サンプルコード
from transformers import AutoTokenizer, AutoModelForSequenceClassification,BertJapaneseTokenizer
from transformers import pipeline
model = AutoModelForSequenceClassification.from_pretrained('daigo/bert-base-japanese-sentiment')
tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
nlp = pipeline("sentiment-analysis",model=model,tokenizer=tokenizer)
歌詞分析
分析対象
分析対象の曲はこちらです。なんとなくポジネガがよく出そうな曲を選びました。
- ICHIDAIJI
- DENKKOUSEKKA
- トゲめくスピカ
- 阿吽
データの準備
歌詞データは以下のリンクを参照してクロールして取得し、手動で文章ごとにリスト化しました。
歌詞はどこまでを1文とするのか難しいので雰囲気です。
WordCloudで凛として時雨の歌詞の傾向を可視化する - Qiita
ICHIDAIJIの例 ※歌詞は一部モザイク化しています。

データ分析、可視化
■ サンプルコード
#ICHIDAIJI 分析
ichi_list = []
for i in ichi:
result = nlp(i)
ichi_list.append([i,result[0]['label'],result[0]['score']])
ichi_df = pd.DataFrame(ichi_list,columns=['Lyric', 'Posi_Nega', 'Score'])
ichi_df['Mod_Score'] = ichi_df['Score'].where(ichi_df['Posi_Nega'] == "ポジティブ",0-ichi_df['Score'])
xmin, xmax = 0 , len(ichi_df)
plt.hlines([0], xmin, xmax, "red", linestyles='dashed')
ichi_df['Mod_Score'].plot(title="ichidai")
各文章ごとのスコアをDatarameに格納しています。
スコアがポジティブでもネガティブでも0から1の間で返ってきて可視化しにくいので、ネガティブの場合は、0から-1の値に変換してMod_Score列に格納しています。

上記のMod_Score列を可視化するとこんな感じ。
0がニュートラルで1に近づくとポジティブ、-1に近づくとネガティブ要素が強い文章となっています。
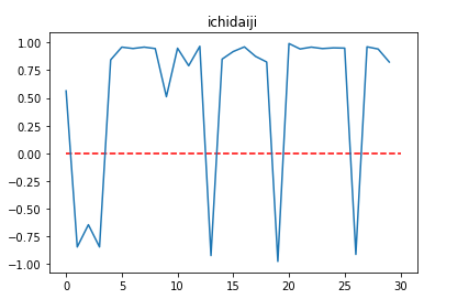
分析結果
ICHIDAIJIと同じ要領で、残りの3曲を分析し、可視化した結果が以下となります。
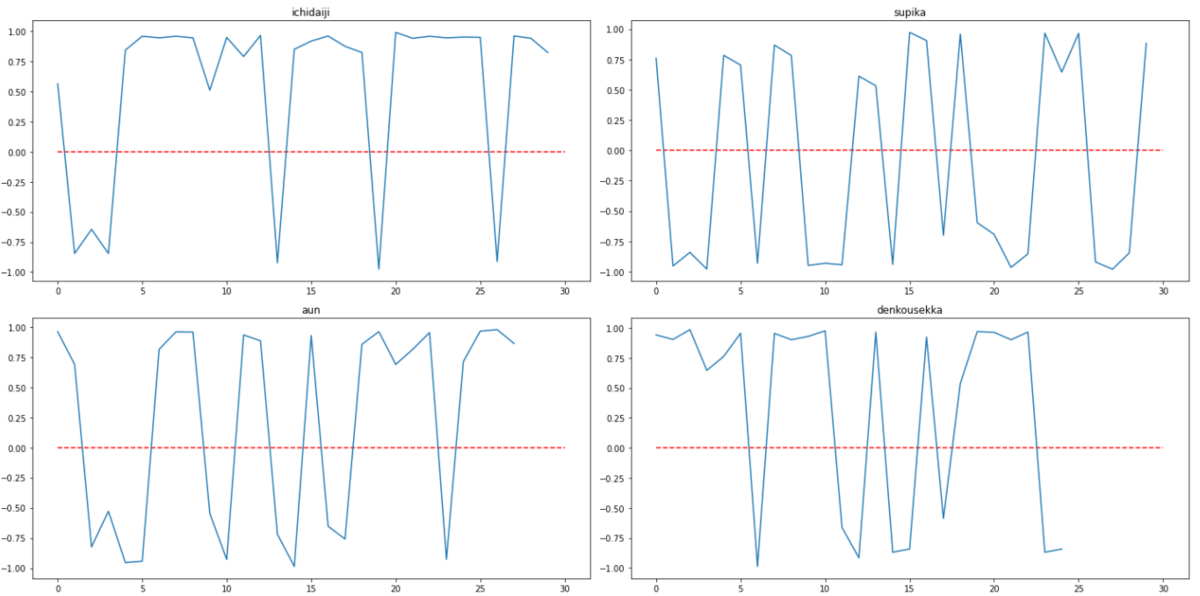
トゲめくスピカ、阿吽は恋愛ソング(片思い、告白)なので、感情に起伏が激しいかなと想像していましたが、結構想像どおりで面白い。
DENKKOUSEKKAはもっとイケイケかと思いましたが、思ったよりって感じです。ただ、歌詞が結構はっちゃけているので歌詞だけで感情分析するのは難しいのかもしれません。
平均スコアを見てみるとこんな感じ。平均にしてみると曲のイメージに近い感じになりました。
- ICHIDAIJI : 0.539080
- DENKKOUSEKKA : 0.344485
- 阿吽 : 0.219658
- トゲめくスピカ : -0.089131
最後に
BERTを使って歌詞の感情分析をしてみましたが、思ったよりも精度が高そうな感じです。ただ、BERTの仕様の問題なのかニュートラルな文章が少なく、ニュートラルっぽい文書はポジティブの分類されてそうなので、注意が必要です。今回4曲だけやりましたが、全曲分析してみるとアーティストごとの歌詞の感情の傾向とか見れるようになって面白そう。
参考サイト
- BERT_HANDSON/BERT_HANDS_ON.ipynb at master · ydaigo/BERT_HANDSON · GitHub
- Python で日本語文章の感情分析を簡単に試す (google colab で試す) - Qiita
