これはなに?
ポルカの歌詞データ使って色々分析してきましたが、今回はUniversal Sentence Encoderという文章を数値化する仕組みを使って、歌詞どうしの類似度算出をやってみます。
Universal Sentence Encoderとは
Googleが開発した文章を数値化(ベクトル化)する手法です。
詳細は以下の記事を参照してください。
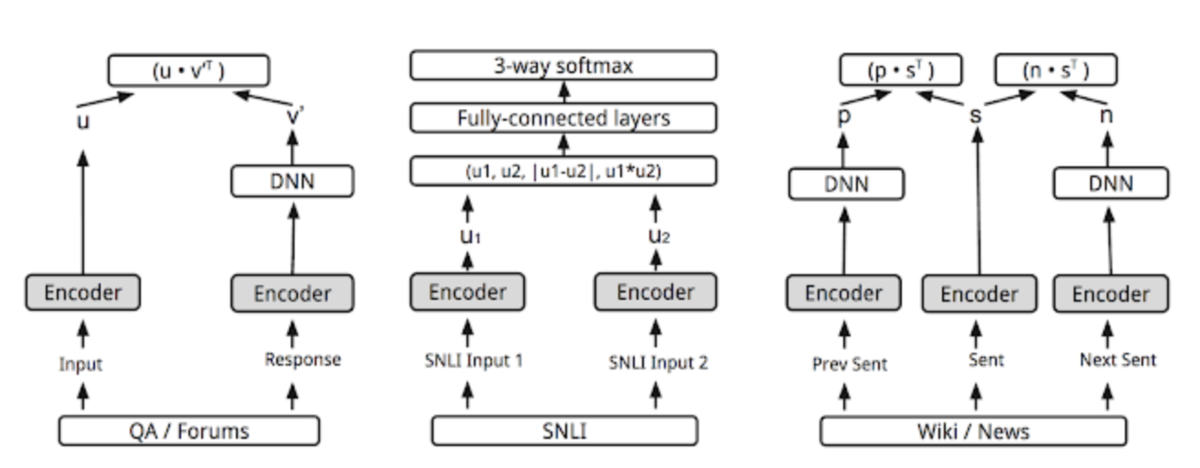
自然言語処理におけるEmbeddingの方法一覧とサンプルコード - 機械学習 Memo φ(・ω・ )
■ モデル
tfhub.dev
やること
ポルカ歌詞データの文表現ベクトルを作成し、各曲のベクトルどうしの内積を取ることで類似度を取得します。取得した類似度の結果をPythonのライブラリを使って、ヒートマップやネットワークグラフ図で可視化してみます。 あくまで文書の類似度を見ているので、曲調は今回の類似度には含んでいません。
■ イメージ図

環境
今回も以下の記事のDocker環境を利用します。分析に必要なライブラリ入れまくっていたら、Docker Imageが10GB超えてた...
歌詞分析
早速歌詞分析やっていきます。ソースコードはブログの最後に記載します。
歌詞データの取得
以下の記事を参考に、歌詞データを取得します。
WordCloudで凛として時雨の歌詞の傾向を可視化する - Qiita
取得した結果は以下のような感じです。

類似度算出
2曲の歌詞をUSEで分析し、類似度を算出します。1に近づくほど、類似度が高い曲となります。

分析のための前処理はこれで終わりなので後は可視化とか色々やってみます。
各曲の一番歌詞が似ている曲リスト
各曲の歌詞データが一番似ているリストは以下のようになりました。
例えば、「阿吽」を見てみると、「トゲめくスピカ」が一番歌詞が近い曲になります。どちらも恋愛模様を歌にした曲なので、歌詞を見比べてみると相手のことを君と呼んでいたり、たしかに似ている雰囲気があります。

類似度が高い順でソートしてみました。
「リスミー」がアレンジショートVerの「リスミー (かかってこいよ武道館 ver.)」とかなり類似度が高いのは、歌詞がほぼ同じなので納得がいきますね。

グラフネットワーク
各曲の類似度が最大の曲どうしを繋げてネットワークにしてみました。面白いことに6つのグループになりました。色が濃い丸がリンクが多い(ページランクが高い)曲になります。トゲめくスピカが5曲との類似度最大曲となっていました。
各グループにラベルつけたかったけど、思い浮かばなかったので、何か思い浮かんだ方いれば教えてください!

ページランクのランキングは以下のようになります。有名どころが多い気がするので、周辺の曲はどこかインスパイアされた曲が多いのかもしれませんね。

ヒートマップ
最後にヒートマップで曲どうしの類似度を可視化してみました。色が濃いほど類似度が高い曲の組み合わせです。
「顔も覚えていない」などの比較的に色が薄い曲は、かなりユニークな歌詞であると言えます。「顔も覚えていない」は、「イエイエ顔も覚えてない」を連呼してるような曲なので特殊ですよね笑

ソースコード
gist662a890195f159c015abaf6ef73aa996
最後に
Universal Sentence Encoderを使って、ポルカの歌詞データの類似度算出をやってみましたが、Googleが高性能なモデルをOSSで提供してくれているおかげて、ローコードで分析することができました。ぱっと見た感じだと結構精度がでているように見えました。
以下の記事のような学生の論文の類似度算出してコピペを見つけるとか想像よりも簡単にできそうですね(恐怖
Notice Board | CopyMonitor - 【コラム】学生のコピペ論文問題とCopyMonitor活用例1(教員編)
